


导读:数据只有流动起来才可以产生价值。基于IOTA架构的数据河与数据湖组建企业内部的可流动的大数据水系,用数据驱动整个企业精益成长。
数据湖(Data Lake)在Wiki中定义如下:

简而言之,数据湖是按存储原始数据格式的数据存储,旨在任何数据可以以最原始的形态储存,可是结构化或者非结构化数据,以确保数据在使用时可以不丢失任何细节,一般以Hadoop系统存储为比较典型的解决方案,所有的实时数据和批量数据,都汇总到数据湖当中,然后从湖中取相关数据用于机器学习或者数据分析。一个典型数据湖的结构如下图所示:
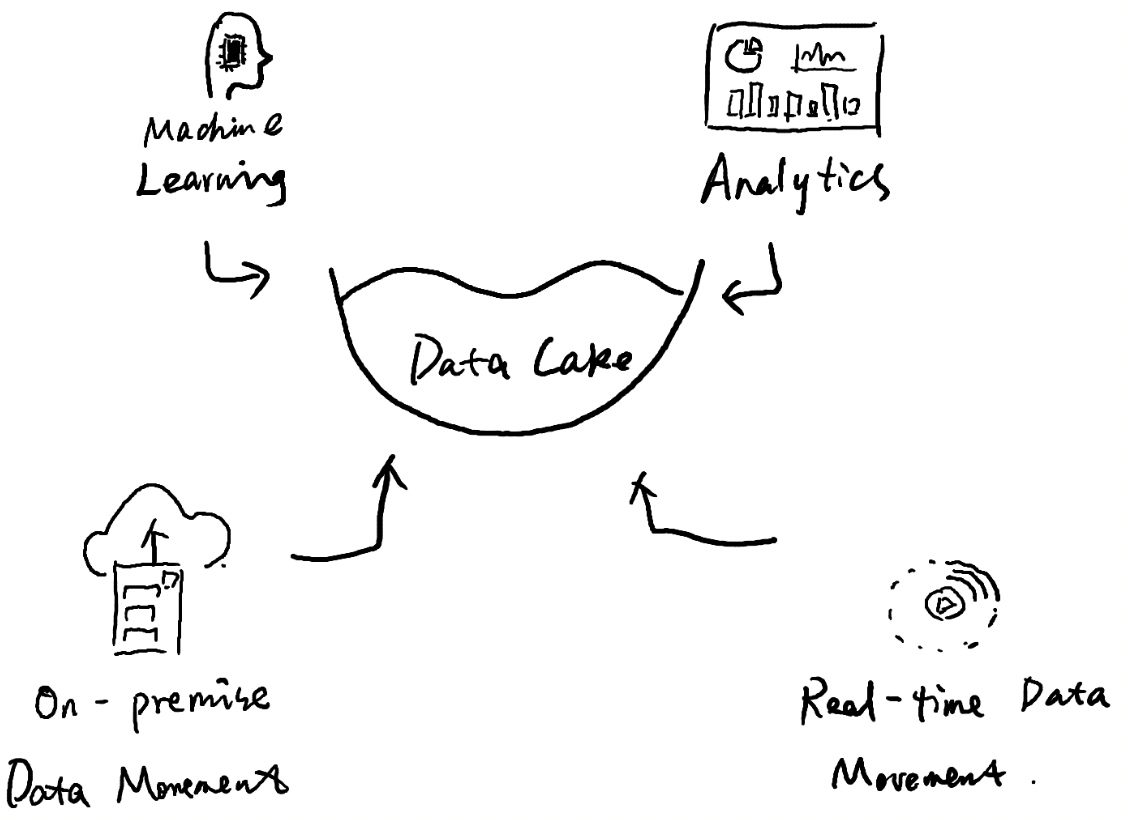
图1:数据湖存储着企业各种各样的数据
(感谢杨欣元同学的配图)
数据湖的概念被企业中广泛用于大数据平台的存储与使用,替代了原有数据仓库体系当中的ODS(operational data store)存储企业中各种各样的数据。在易观,SDK的月活达到5.9亿,当易观的数据湖达到6.8Pb都无法存储半年数据的时候我意识到这个问题:
“这样真的是对的么?数据一味的堆积,等待被使用时才调用? ”
企业的业务是实时在变化的,这代表着沉积在数据湖中的数据定义、数据格式实时都在发生的转变,企业的大型数据湖对企业数据治理(Data Governance)提升了更高的要求。大部分使用数据湖的企业在数据真的需要使用的时候,往往因为数据湖中的数据质量太差而无法最终使用。数据湖,被企业当成一个大数据的垃圾桶,最终数据湖成为臭气熏天,存储在Hadoop当中的数据成为无人可以清理的数据沼泽,最终以为TCO(Total cost of ownship)过高而被企业所抛弃。
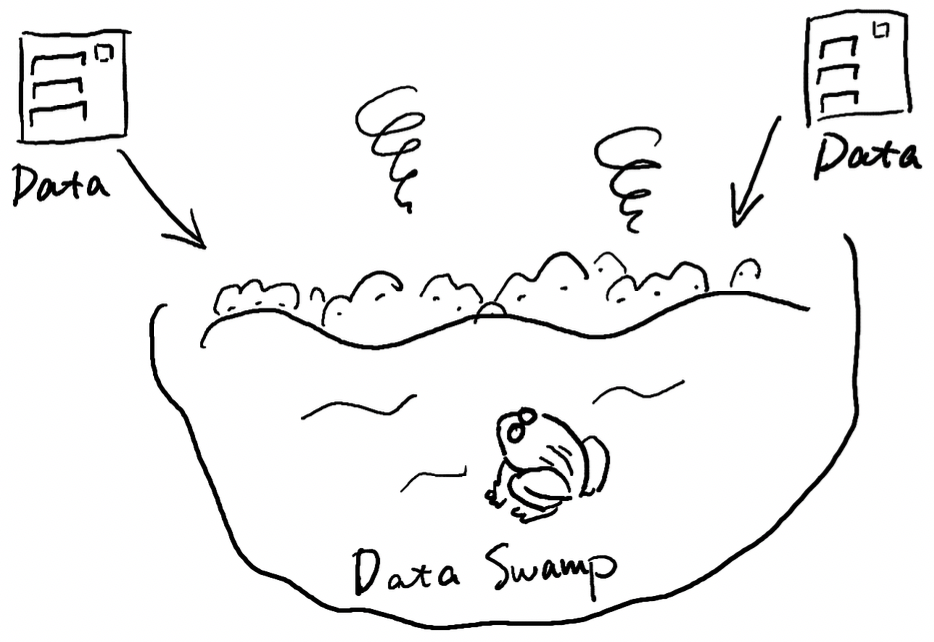
图2:缺乏数据治理的数据湖会成为数据沼泽
这个时候我意识到:
“大数据,不被有效使用就会成为大垃圾。”
如何让大数据的水保持清亮不会成为数据沼泽?中国有句谚语:“流水不腐,户枢不蠹”。数据只有流动起来,才可以不成为数据沼泽,湖泊只是暂存数据河流的基地。数据流动就意味着所有的数据产生,最终要有它的耕种者和使用者。要让数据有效流动起来,就要建立有效的“数据河”(Data River)。
“什么是数据河?”
数据河(Data River)就是在由源头产生清晰干净的有效数据(去ETL化,数据源头业务就像生态水源一样,不让污水流下去),通过各个河流网,流向各个数据消费端的架构。
数据河的特点如下:
• 源头有效:根据大数据IOTA架构,数据河在产生的源头就需要加工为有效的CDM数据(Common Data Model),参见文章《Lambda架构已死,去ETL化的IOTA才是未来》,数据通过数据耕种方和使用方直接在数据产生源头通过Edge SDK 进行清洗。
• 全局唯一:多条数据河的差别在于CDM模型的不同,而不是使用者的使用方法不同,避免同样数据源被多次加工失去数据唯一性。
• 高低流向:数据河一定是要有高低流向,即每条河流都需要有确定的使用者,而不是漫无目的的洪水,数据源头的质量是通过环境治理由使用者定义的,而不是由产生者,产生者只关注数据是真实即可。
• 湖中暂存:数据河一定是基于IOTA架构的实时数据,在CDM模型的支持下,实时流向使用者。数据河在数据湖中只是暂存,一定会流向其他河流和分支,而不会沉积在数据湖中,否则会产生数据淤泥,最终成为数据沼泽。
最终一个企业内部由多条河流组成一个公司内部的数据生态(Enterprise Data Eco System ):
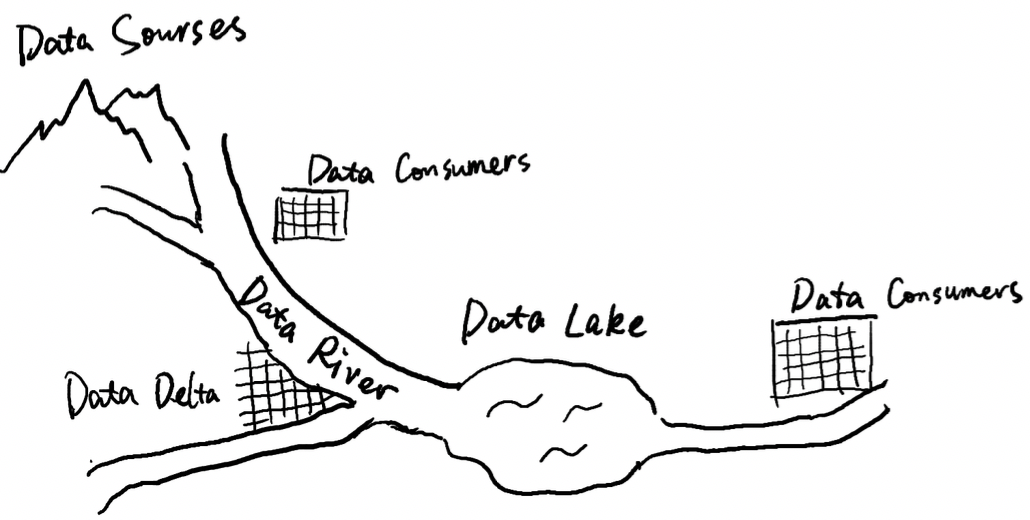
图3:由数据河组成的公司数据生态
• 数据源头(Data Source):数据产生者,确保产生的数据都是真实数据,像冰川雪水一样确保数据真实性。通过边缘计算,变为IOTA架构当中的CDM模型,确保CDM全局唯一,不用管数据业务统计的计算逻辑。
• 数据河(Data River):有全局CDM模型唯一定义的,由数据源头流向数据消费者的数据架构,可以使用大数据IOTA架构或者其他类似的去实时数据处理架构。
• 数据消费者(Data Cosumer):数据消费方,拿到原始真实的数据,根据自己的业务逻辑,实时计算为自己所需要的结果或者根据数据实时驱动自己的业务。(整体是去ETL化的,参考Lambda架构已死,去ETL化的IOTA才是未来)
• 数据三角洲(Data Delta):多条数据河交汇使用的地方,需要数据耕种者(Data Cultivators)把两个不同的CDM模型(例如用户行为数据的CDM与商品库存数据的CDM),实时合并,提供给数据消费者实时驱动自己的业务。一般,三角洲的河流交汇越多,这个三角洲的土壤更加肥沃。数据三角洲的耕种,可以通过AI或者机器学习会产生新的数据源,在新的CDM模型和使用者的支撑下可以是新的数据源头(Data Source)。
• 数据湖(Data Lake):在河流交汇或者河水需要暂存下来的时候,这是根据数据耕种者的需要,其中的数据一定是要继续流动的,而不是死水,即数据在数据湖中暂存时间是有限的,例如3个月或者6个月,最终在数据消费者这里才是永久保留。
这个模式比较典型的一个实现就是易观方舟,易观方舟以IOTA架构安装到企业内部,帮助企业建立用户行为分析这个CDM的数据河,以“主、谓、宾”的模式打通企业内部用户的各种行为,直接提供给产品和运营做相关的数据分析,同时也是一个PaaS平台,可以供给给其他数据耕种者继续再次加工。
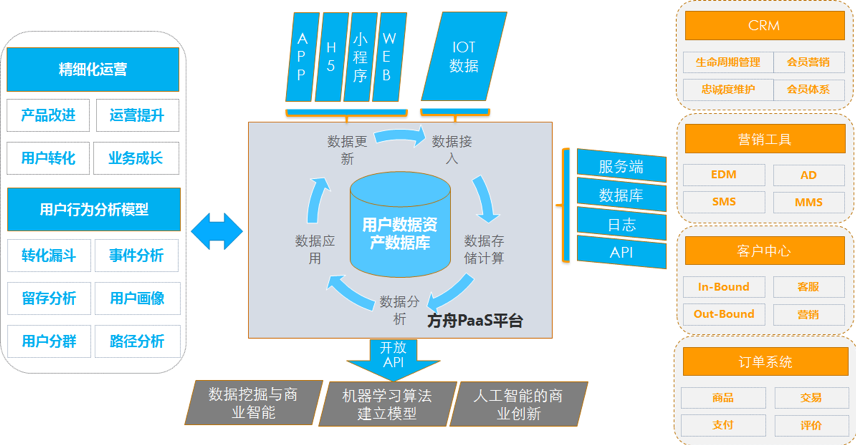
数据河是数据驱动中台的最终架构,只有让数据流动起来不断消费才可以让数据不断的自我更新迭代数据质量,不断自我加强才可以实现数据驱动业务。
数据,只有流动起来才可以产生价值。宁要IOTA架构下的数据河,不要Lambda架构下的数据湖。
2018易观A10峰会

价值1500元的峰会「5人团体两日通票」尊享来袭
九大分论坛,呈现50余场干货演讲
48小时精彩放送不停歇
结伴前行,共同成长
共享年度大数据巅峰盛典
戳这里,参与优惠活动吧~