


导读:HDFS作为Hadoop生态系统的分布式文件系统,它被设计用来存储海量数据,特别是TB、PB量级别的数据。它的设计的初衷也是存储大文件,而如果HDFS上存在大量的小文件,会对系统性能带来严重的问题。本文想跟大家聊下小文件的处理。
本文的小文件是指那些大小比HDFS的block (Hadoop 2.x的默认大小128MB)小的多的文件。在HDFS中,文件元信息,例如位置、大小、分块信息等这些存储在Namenode的内存中,每一个object占用150 bytes的内存。文件个数越多相应的也会占用Namenode更多的内存。何况HDFS主要是为了流式的访问大文件而设计的,读取众多的小文件显然也是非常低效的。
▌Hadoop小文件的3类常见情况的处理
1、HDFS中存储包含了大量小文件
现象:在HDFS上已经存在了大量的小文件和目录。
方案:通过调用HDFS的sync()方法和append()方法,将小文件和目录每隔一定时间生成一个大文件,或者可以通过写程序来合并这些小文件。
2、MapReduce的输入包含大量小文件
现象:输入文件中存在大量的小文件
MapReduce程序的Map任务(task)一次可以处理一个块(block)大小的输入数据(默认使用FileInputFormat)。如果一个输入文件的大小大于block,那么会拆成两个或多个task进行处理;如果小于block,也会用一个task处理该文件。需要处理的数据如果分散存储在许多小文件中,就会产生大量的map task,如果小文件个数非常多,这会使处理时间变的很慢。
方案:有3种
1)Hadoop Archive:
Hadoop Archive是一个高效地将小文件放入HDFS块中的文件存档工具,它能够将许多小文件打包成一个HAR文件,这样会同时减少Namenode的内存使用。
2)Sequence File:
Sequence File由一系列的二进制key/value组成,如果key为小文件名,value为文件内容,则可以将大批小文件合并成一个大文件。
1)和2)这里不做介绍,可以参考
http://blog.cloudera.com/blog/2009/02/the-small-files-problem
3)CombineFileInputFormat:
Hadoop有一个专门的类CombineFileInputFormat 来处理小文件,它根据一定的规则,将HDFS上多个小文件合并到一个InputSplit中,同时启动适量的Map来处理这里面的文件,以减少MR整体作业的运行时间。CombineFileInputFormat类继承FileInputFormat,主要重写了List<InputSplit> getSplits(JobContext var1)方法,我们可以设置mapreduce.input.fileinputformat.split.minsize.per.node、mapreduce.input.fileinputformat.split.minsize.per.rack和mapreduce.input.fileinputformat.split.maxsize 参数的设置来合并小文件。其中mapreduce.input.fileinputformat.split.maxsize参数至关重要,如果没有设置这个参数(默认没设置),那么同一个机架上的所有小文件将组成一个InputSplit,最终由一个Map Task来处理。如果设置了这个参数,那么同一个节点(node)上的文件将会组成一个InputSplit。
InputSplit包含的HDFS块信息存储在CombineFileSplit 类中。该类包含了每个块文件的路径、起始偏移量、相对于原始偏移量的大小和这个文件的存储节点。CombineTextInputFormat告诉MR程序如何读取组合的InputSplit,具体如何解析CombineFileSplit中的文件主要在CombineFileRecordReader中实现。该类封装了TextInputFormat的RecordReader,并对CombineFileSplit中的多个文件循环遍历并读取其中的内容。
样例代码如下:

日志输出:
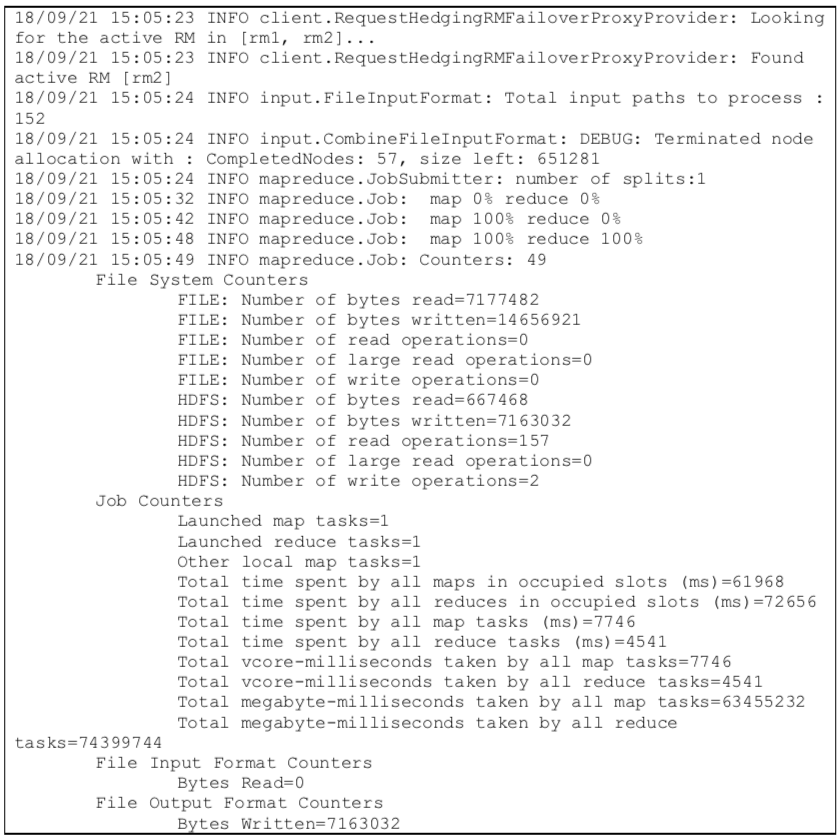
可以从日志中很清楚的看出input文件数为Total input paths to process : 152,通过CombineFileInputFormat处理后splits为mapreduce.JobSubmitter: number of splits:1,map数为Launched map tasks=1。可以修改mapreduce.input.fileinputformat.split.maxsize参数,观察Map Task的个数变化。
3、Hive小文件问题
现象1: hive输入的文件过多
方案:设置mapper 输入文件合并参数

现象2:hive执行中间过程生成的文件过多
方案:设置中间过程合并参数,尽量避免小文件
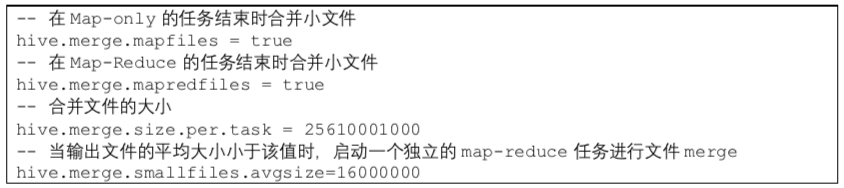
现象3:hive输出结果生成的文件过多
方案:一种是调整reducer个数,另一种是调整reducer大小

/ 参考文章 /
1、https://hadoop.apache.org/docs/r2.7.1/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
2、https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
3、http://blog.cloudera.com/blog/2009/02/the-small-files-problem/
2018易观A10峰会
