


一、hbase-connector平台组件研发——要实现的接口简介
Presto是由facebook开源的一款大数据交互式查询框架,除了facebook之外,在国内像京东、美团等公司都有广泛的使用。前段时间基于HBase开发了presto的connector,由于开发时苦于在网上找不到详细可用的资料,踟蹰前进的走了很多弯路,因此这里把开发过程中遇到的问题和心得整理出来,希望能为其他研发者提供参考,有不准确的地方也请各路大佬多多指教。
开发时因为presto文档的不完善,所以我们需要参考presto提供的例子,但是当我们打开例子时,看到要实现的接口如此众多往往会感到一丝无力。
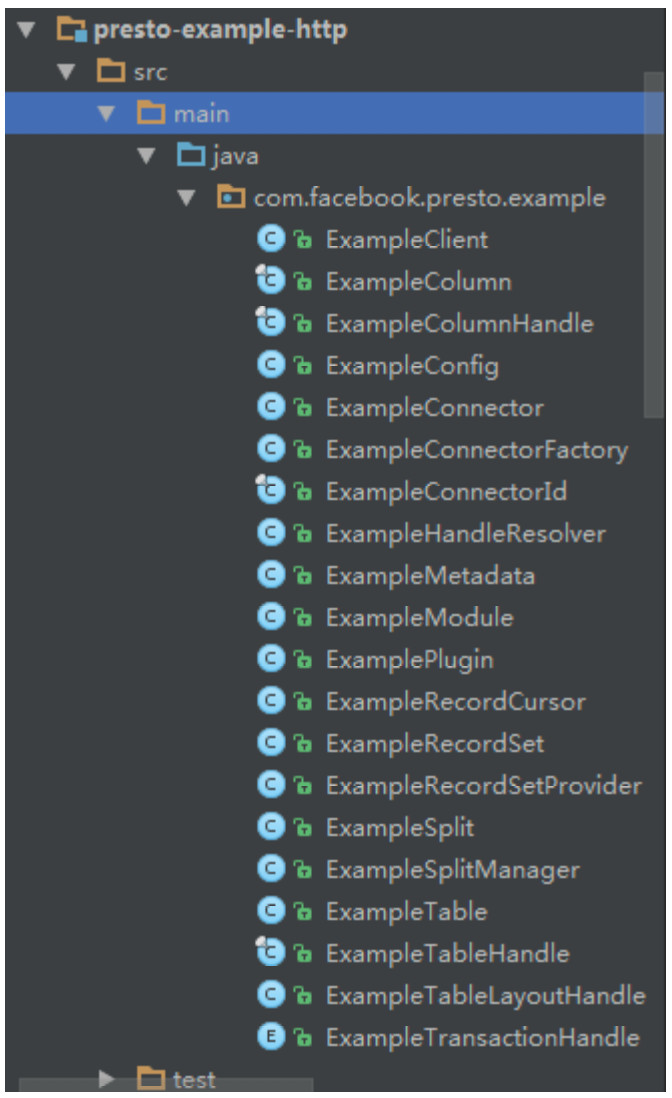
但是实际上这些接口中大部分只需要参考官方例子适当做些修改即可。真正需要由我们写代码实现的只有如下几个接口:
1. ConnectorMetadata
组件元数据相关的操作,例如查询DB中有哪些表、表中有哪些字段、删除表等。
2. ConnectorSplitManager
根据用户的查询条件以及数据的存储特点,将计算任务切分成若干split由coordinator进行并发调度。类似于spark RDD接口中的getSplit方法。
3. RecordCursor
定义应该如何根据拿到的一个split到库中查询数据。像我们在split中封装了StartRowkey和EndRowkey,那么在RecordCursor中就要根据起止rowkey定义Scan对象,对HBase做scan操作了。
如果需要实现写入,则还需要实现这个接口:
4. ConnectorPageSink
定义如何写入数据。
接下来将详细介绍各个接口的实现。
二、hbase-connector平台组件研发——ConnectorMetadata
ConnectorMetadata接口是用来定义与组件相关的元数据操作的。对应到presto控制台中的命令为show schemas; show tables; desc tablexxxxx; drop table;等等。该接口的实现相对比较简单,只需要了解接口含义调用组件API做出实现即可。下面就对各个接口的功能及实现做简要说明。
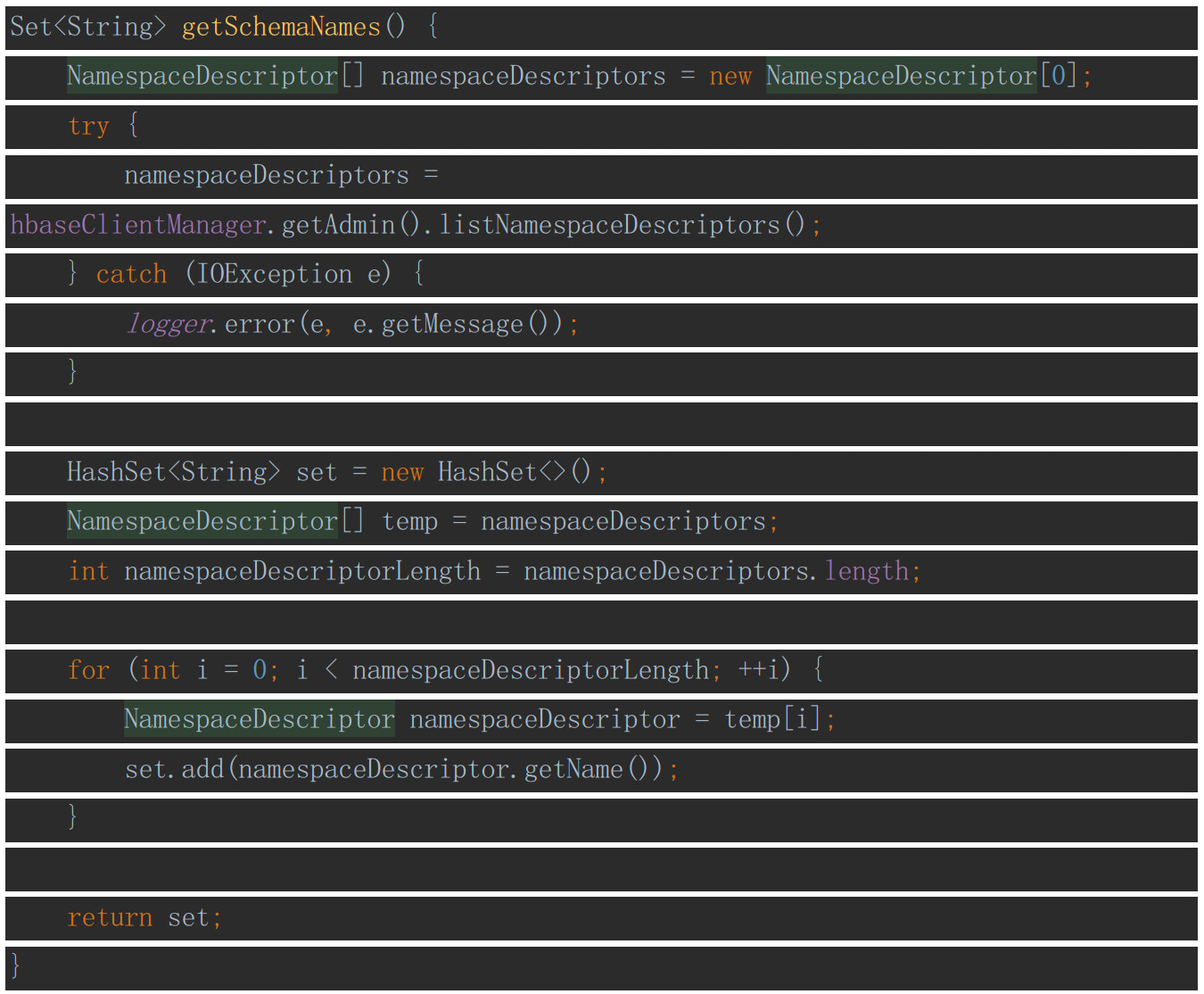
listSchemaNames

该方法对应show schemas命令,用来展示Connector下有哪些DB。接口的实现也很简单,只需要调用HBase的API对DB做查询即可,如下:
getTableMetadata

该方法是一个比较重要的接口,他是用来返回指定HBase表的表结构的。因为HBase中列族固定而字段不固定,所以我们需要有一个存储机制来定义表结构。我们这里是将其存储在MySQL中,至于字段所在列族是根据hashcode取模获得,也可以一并存储在MySQL中。
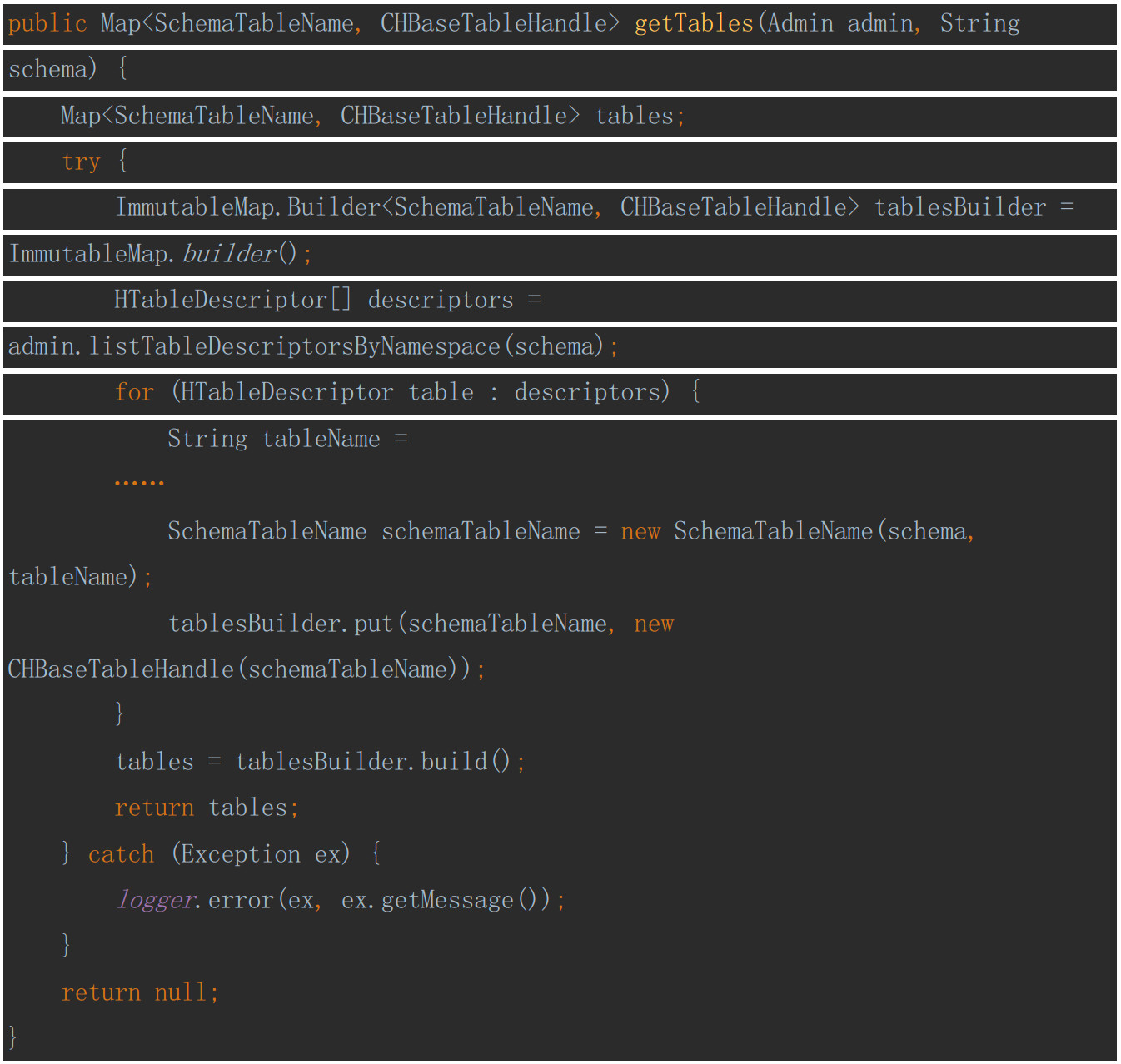
listTables

该方法用来获取指定schema(或不指定)下都有哪些表。最终的实现为:
getColumnHandles

该方法与getTableMetadata作用一致,只不过返回值稍有不同。
listTableColumns

获取指定schema下所有表的元数据信息。
dropTable

用来drop表。实现如下:

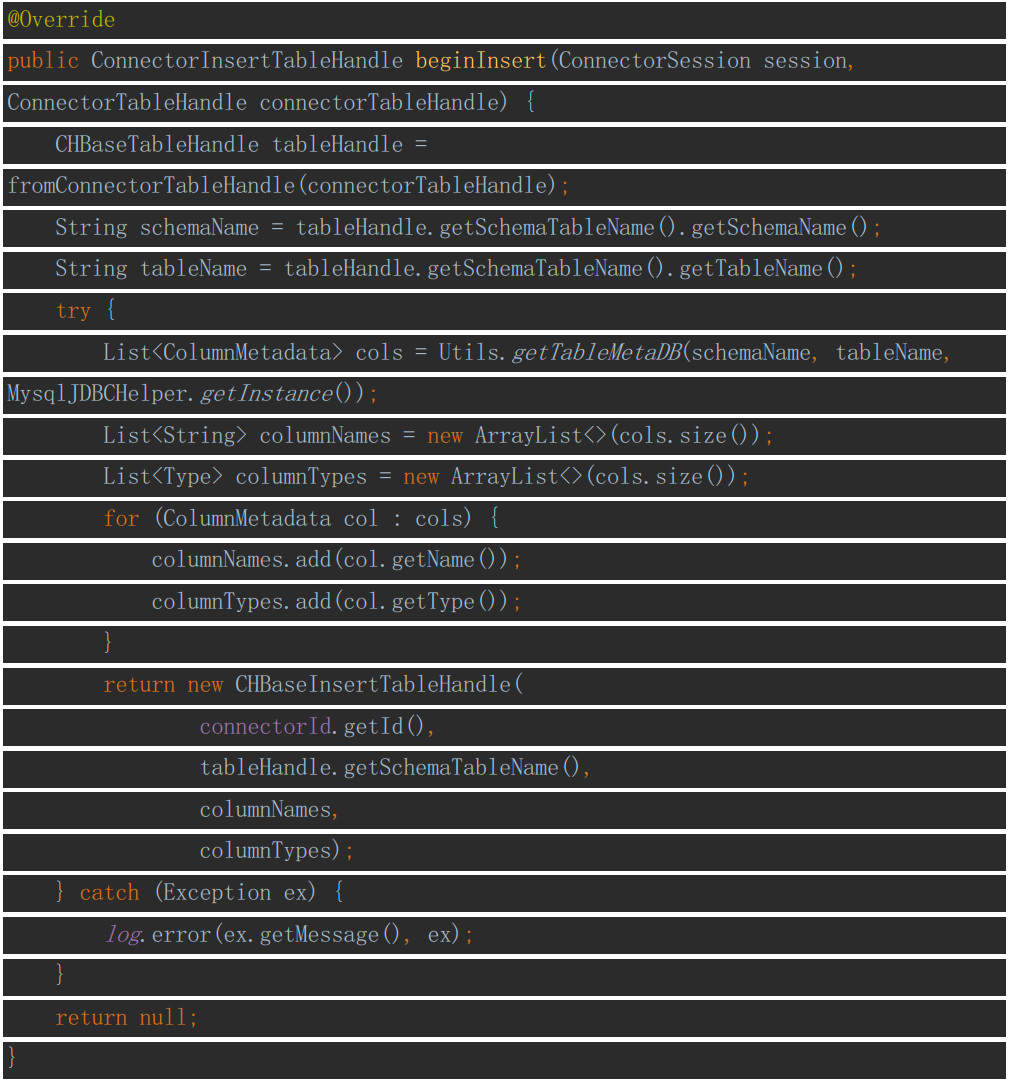
beginInsert

如果需要实现写入操作,则要实现该方法以及finishInsert方法。该方法主要需要将表的字段和数据类型封装到实现了ConnectorInsertTableHandle接口的对象中。实现如下:
finishInsert
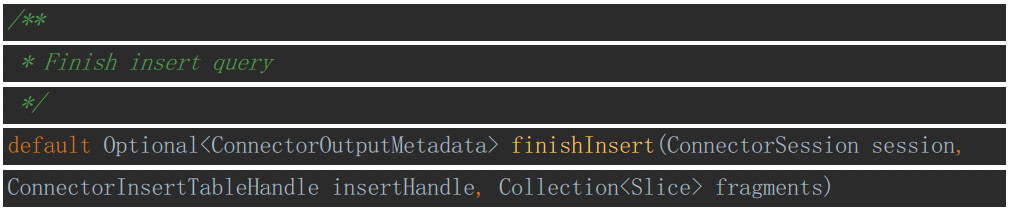
三、hbase-connector平台组件研发——ConnectorSplitManager
ConnectorSplitManager接口用来解析SQL中的查询条件,根据数据存储的特点将计算任务切分成多个split,交由coordinator调度到各个节点执行。该接口的作用类似于Spark RDD中的getSplit方法。
以下是该接口中唯一的待实现方法:

该方法需要返回一个FixedSplitSource对象,该对象中用List封装了我们人工切分出的若干个Split,Split对象中封装了所读数据的元数据信息,例如namespace名、表名、(HBase相关的StartRowKey、EndRowKey)、字段名和字段类型等等。Coordinator会将该接口返回的这些Split逐一分发给不同Worker,由其构建一个RecordCursor对象,再进行读取操作。
以下是一个简单的例子:

使用盐值切分Split
经过我们的测试得知,从HBase读取同样数量的数据,如果采用多线程并发的方式进行,性能会比单线程查询提升10~20倍,因此我们这里采用了在RowKey前加00~29两位盐值的方式,将一份数据分割成30个Split,保证了数据的并发性。
谓词下推
不做任何谓词下推的情况下,我们会将数据整个扫描出来,然后在Presto的Worker中将符合筛选条件的数据过滤出来。这样会导致Presto Worker需要从数据存储层(即RegionServer)读取大量不需要的数据。造成不必要的系统开销。
谓词下推是指将数据的筛选下推到数据库的存储层,只返回查询所需的数据,这样可以极大的减少返回的数据量。
使用谓词下推优化查询在HBase Connector中又分为以下两种情况:
特定表的特定字段作为谓词
举例来说,在我们的业务场景中,大部分的查询会发生在事件表event中,其中90%以上的查询都会根据事件类型xwhat和日期date做筛选,因此我们将event表的RowKey设计成如下形式。
{盐值}\001{xwhat}\001\{date}…
在拼接起始RowKey时,判断如果查询的表是event,并且有根据xwhat和date字段做筛选,会将这两个字段拼接到起始RowKey中做Scan的起止RowKey。
其余谓词
RowKey中能够拼接的查询条件是有限的,而且字段的顺序也是固定的,当出现查询条件无法通过RowKey做范围Scan时,就需要我们结合HBase的Filter API在RegionServer上做数据筛选。关于这一部分的描述,将在RecordCursor接口中详细描述。
如何获取谓词列表
获取谓词列表conditions的代码:
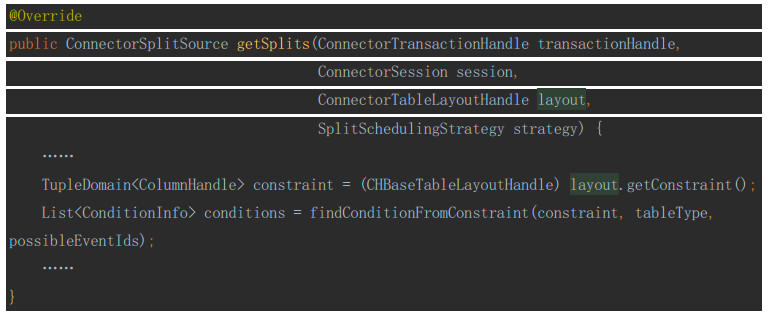
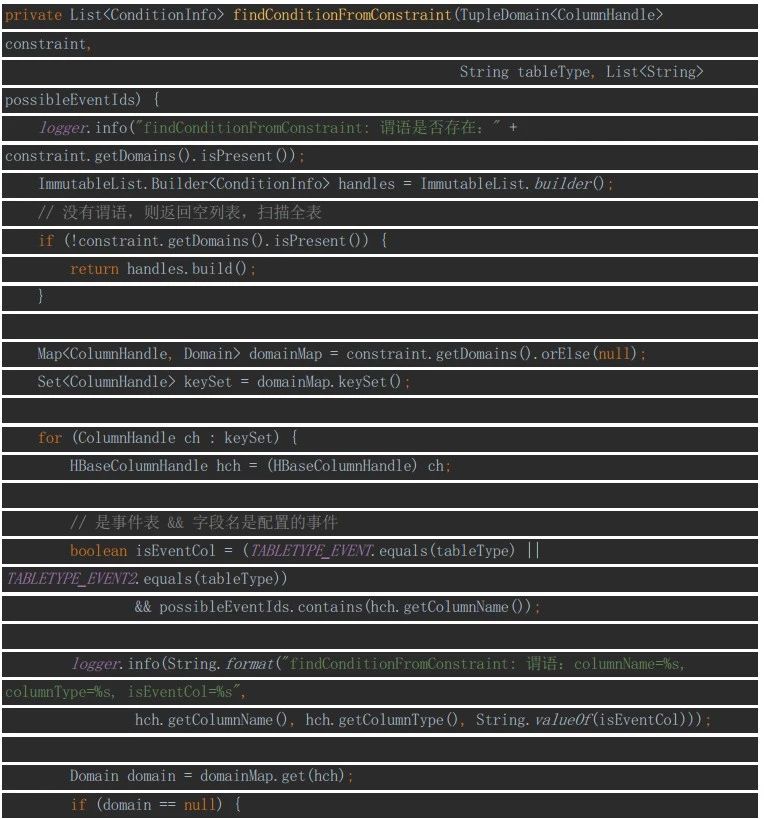
findConditionFromConstraint方法的实现:
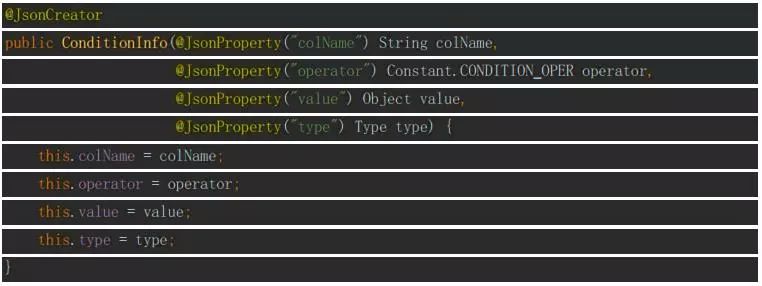
ConditionInfo的构造函数包含四个字段,字段名、查询条件的操作类型、字段的值、字段类型:
如何指定Split要分配到哪个Worker执行
这里解释一下为什么要为Split指定Worker运行。
这是因为在一次查询Job中,不同的子查询由于表数据量和查询条件不同,其数据量大小也不一致,而同一个子查询切分出的若干Split,其数据量是大致相等的。如果采用随机分配的方式,有可能造成多个大Split分配到某一个Worker上执行,造成单点压力过高影响整体运行效率。因此我们需要将每一组Split均分到所有的Worker上。
以下代码节选自Presto的SimpleNodeSelector类的computeAssignments方法,由这段代码可以看到,Coordinator会根据Split的isRemotelyAccessible属性判断要分配到指定Worker上执行,还是随机分配到某个Worker上执行。

所以需要在ConnectorSplit的构造函数中,将isRemotelyAccessible属性置为false即可。
另外这里还有一个坑就是presto在识别Worker时是识别IP不识别Hostname的,所以ConnectorSplitManager的getSplit方法中,可用Worker要设置成IP。而端口则设置为8285即可。如下:

presto中的两个配置项为:

四、hbase-connector平台组件研发——RecordCursor
这个接口是presto connector开发中非常重要的一个接口,他负责从第三方存储框架中读取数据。
数据一旦被connector从存储层读取到presto中,剩下计算的工作就完全交给presto进行处理也就与connector无关了,因此我们如果要对connector的性能做优化,主要就是针对其读取数据的能力做调优。而RecordCursor接口就是其中的一个重要环节。
同时,这个接口也是存储层与业务逻辑层之间交互的中间环节。比如说,我们的业务逻辑要求在存储层以1和0代表true和false,就需要在这个接口中进行数据转义。
以下对几个主要的接口进行讲解。
构造函数
在构造函数中,我们需要解析在SplitManager中封装好的Split对象,根据Split定义的元数据定位到我们要读取的数据块。如果能拿到谓词,还需要结合谓词对数据在RegionServer端做进一步的筛选,以缩小扫描数据的范围。
以我们的HBase Connector为例就是实例化Scanner对象,获取Iterator。如下:

PS:谓词下推的部分我们会单独介绍。
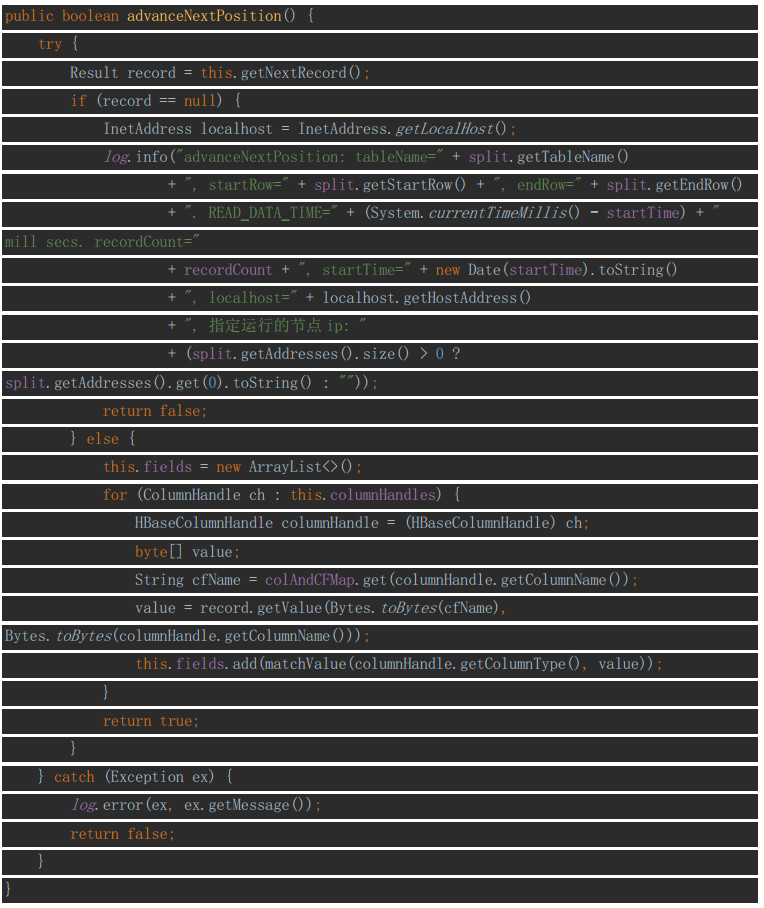
advanceNextPosition
这个接口用来根据构造函数中定义的iterator对象读取一条数据,如果判断有数据返回true,否则返回false。
这里建议大家在发现读取不到数据时,将所读取的表名、数据条数、所耗时间以及当前机器的IP打印出来,便于我们对比性能。
在读取数据时,我们需要遍历入参List<ColumnHandle>对象,按相同的数据将读取到的数据add到List<Object> fields中。代码如下:
在读取数据的getLong、getObject等getXxx方法中,就可以直接以方法入参int field作为索引从fields中读取数据。如下:
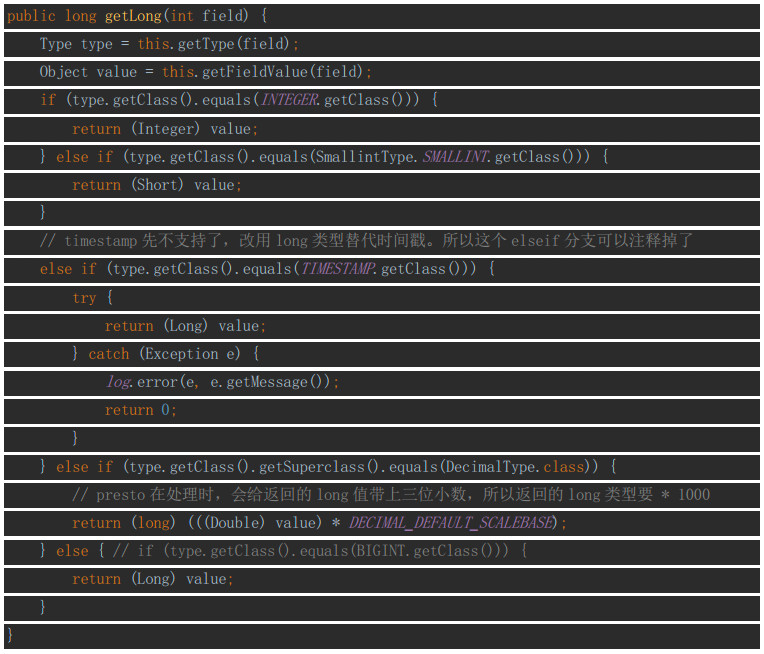
getLong
在RecordCursor接口中,所有整型数据的处理都是在getLong方法中进行的,例如Integer、SmallInt、Timestamp还有Long等等。如下:
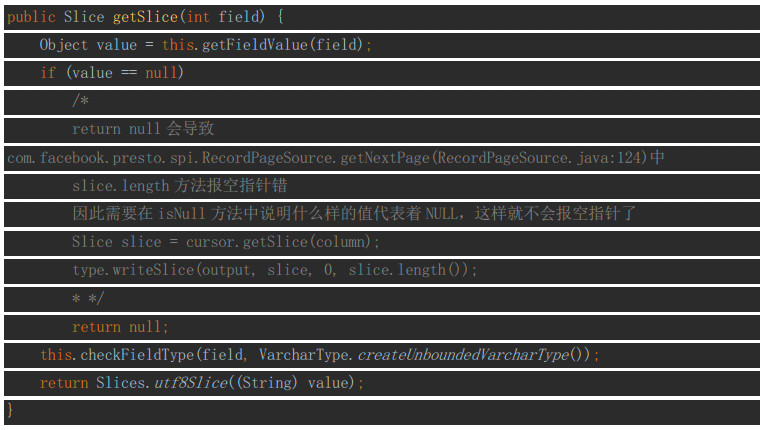
getSlice
对字符串String的处理是放在这个方法中的:
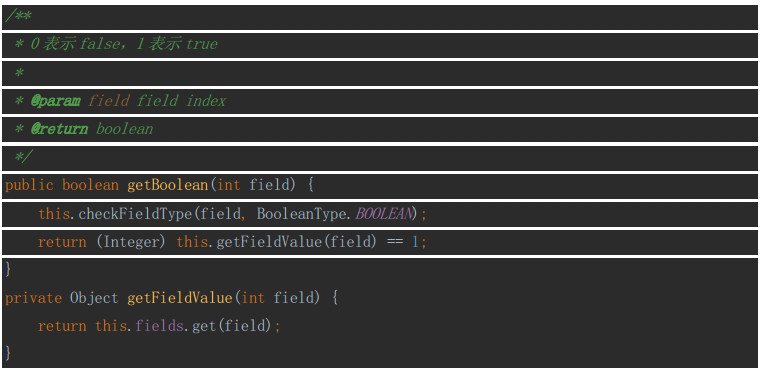
isNull
这个方法用来定义,什么样的数据值,在查询时需要被展示成NULL。
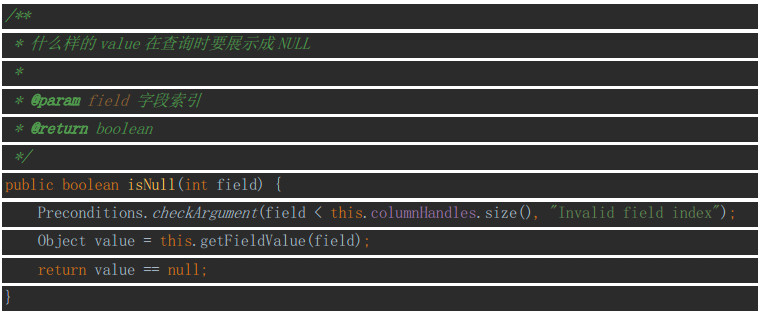
这里需要注意的一点是,在这个方法中如果判断value为null就必须返回true,否则在调用getXxx方法获取其value时,假如value == null,connector就会报Null指针异常。这是因为在presto获取数据时有如下的逻辑:
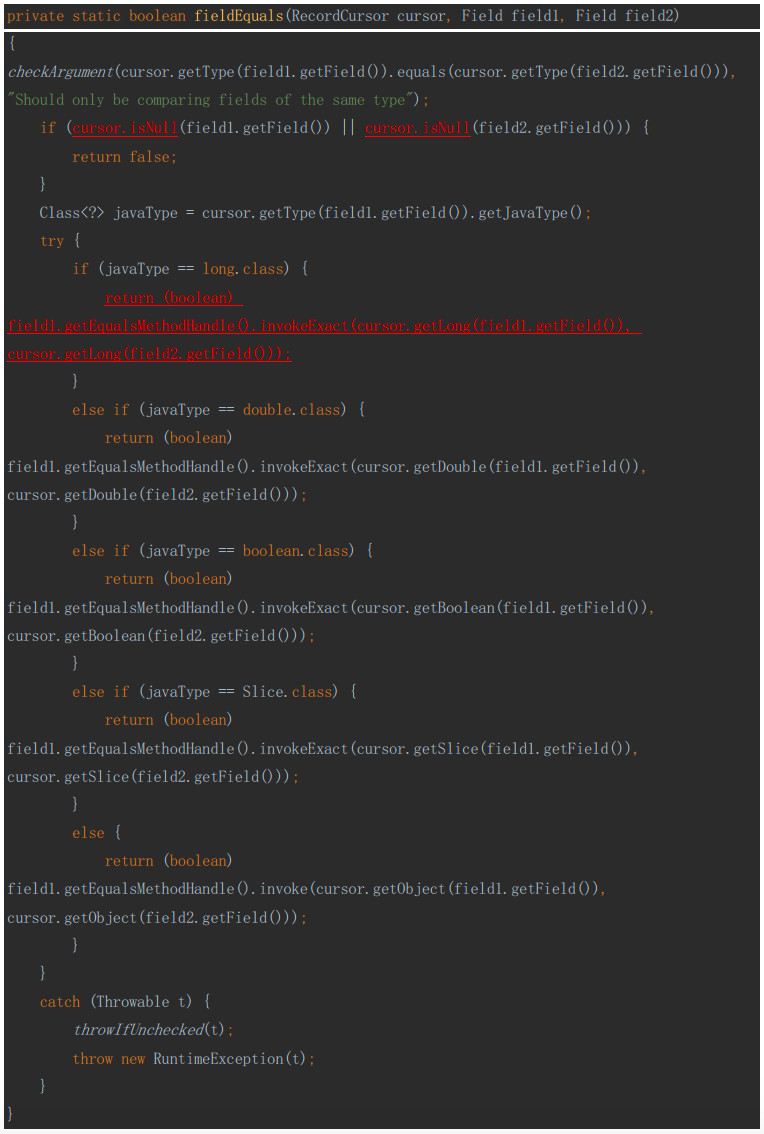
他会先调用isNull判断值是否为null,如果不为null则会直接将getXxx得到的value当做一个非空对象,直接调用他的equalsMethodHandle方法。从而导致空指针异常。
