


导语:
说起MapReduce,只要是大数据领域的小伙伴,相信都不陌生。它作为Hadoop生态系统中的一部分,最早是由Google公司研究提出的一种面向大规模数据处理的并行计算模型。
MapReduce主要由"Map(映射)"和"Reduce(归约)"组成,主要思想是用Map函数用来把一组键值对映射成一组新的键值对,然后指定并发的Reduce函数进行合并输出。然而就是这个简单的分布式思想,却敲开了大数据时代的大门,很多大数据工作者都把学习MapReduce作为基础的一课。 不过对于大多数小伙伴来说,虽然学习或写了很久的MapReduce,却不一定真正研究过它的源码。
这一期,我就先给大家介绍一下MapReduce中Map(映射)的实现者Mapper。更深入的理解MapReduce,在应用到易观千帆技术数据处理方面时,可以更好的提升易观大数据处理能力。
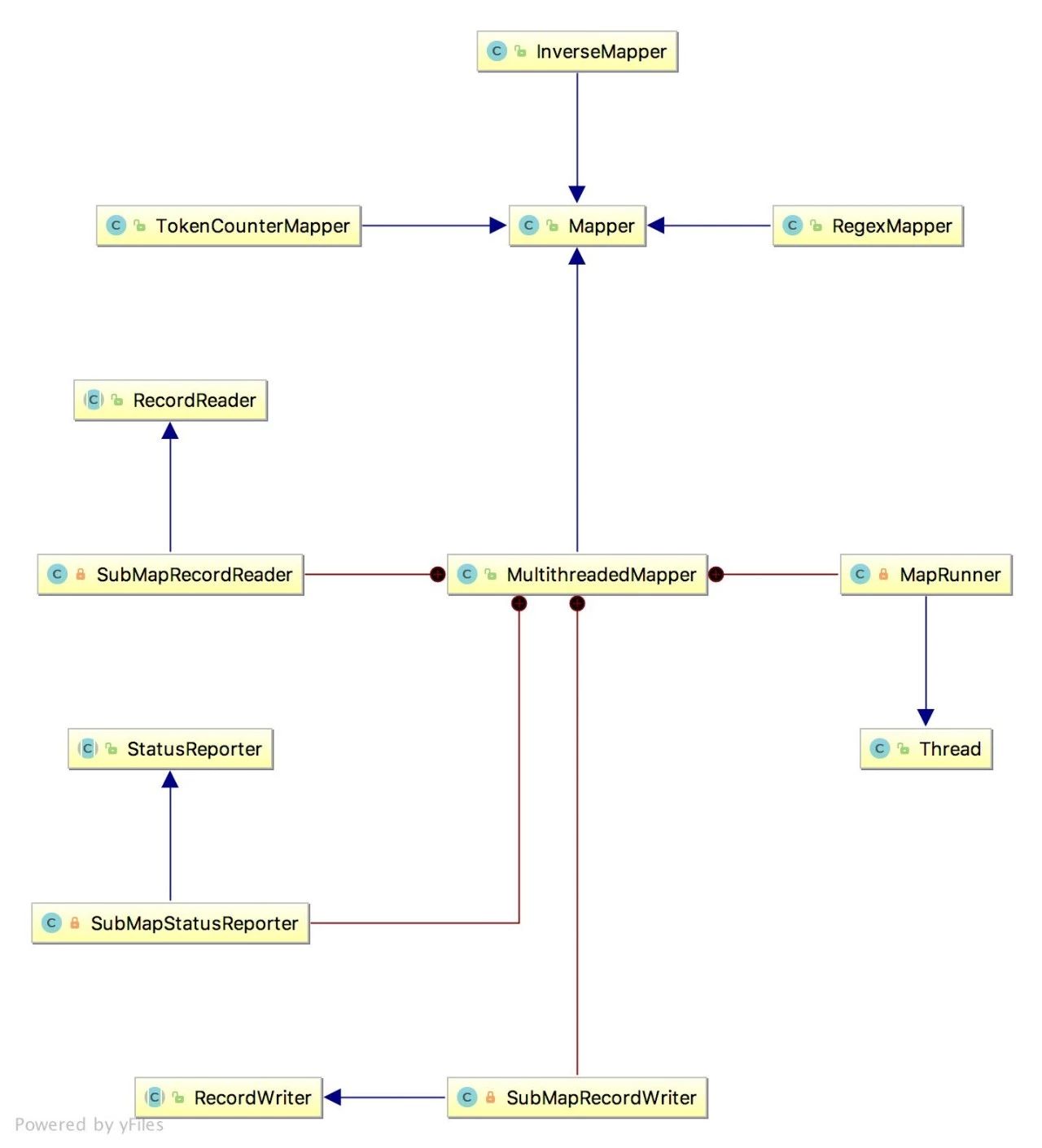
▌类图
如图为Mapper以及它的一些子类的类图(Mapper一共有九个子类。我们挑了其中的4个子类来做分析)
▌Mapper源码

从源码中我们可以看出,Mapper类里总共包含四个方法,一个抽象类。
1.setup()方法—一般作为map()方法的准备工作,如进行相关配置文件的读取、参数的传递;
2.cleanup()方法—是用来做一些收尾工作,如关闭文件、Key-Value的分发;
3.map()方法—是真正的程序逻辑部分,如对一行文本的split、filter处理之后,将数据以key-Value的形式写入context;
4.run()方法—是驱动整个Mapper执行的一个方法,按照run()>>setup()>>map()>>cleanup()顺序执行;
5.Context抽象类—是Mapper里的一个内部抽象类,主要是为了在Map任务或者Reduce任务中跟踪task的相关状态和数据的存放。如Context可以存储一些jobConf有关的信息,在setup()方法中,就可以用context读取相关的配置信息,以及作为key-Value数据的载体。(Context比较复杂,以后可以单独介绍)
▌Mapper子类
InverseMapper

这个类很简单,只是将Key-Value进行反转,然后直接分发,如面包-生产商,我们既可以统计某一种面包来自多少个生产商,也可以统计一个生产商生产多少种面包。不同的需求,利用InverseMapper可以达到不同的效果
TokenCounterMapper

这个类使用StringTokenizer来获取value中的tokens(在StringTokenizer的构造函数中将value按照“\t\n\t\f”进行分割),然后对每一个token,分发出一个<token,one>对,这将在Reduce端被收集,同一个token对应的Key-Value对都会被收集到同一个Reducer上,计算出所有Mapper分发出来的以某个token为key的<token,one>的数量,然后加起来,就得到了token的计数。在我们学习的wordcount程序中,其实只需要在main方法中将job.setMapperClass(TokenCounterMapper.class)进行设置,便可以统计单词的个数。
RegexMapper
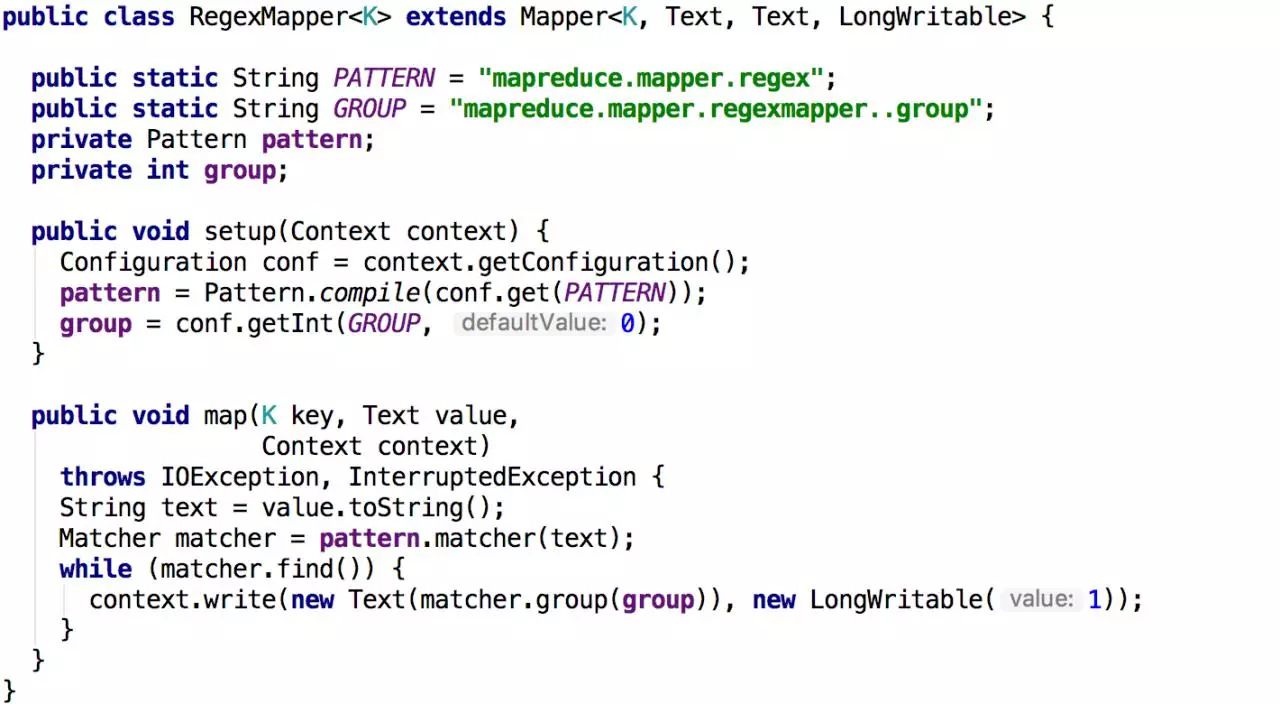
这个类其实就是将wordcount进行了正则化,匹配自己需要格式的word进行统计。
MultithreadedMapper
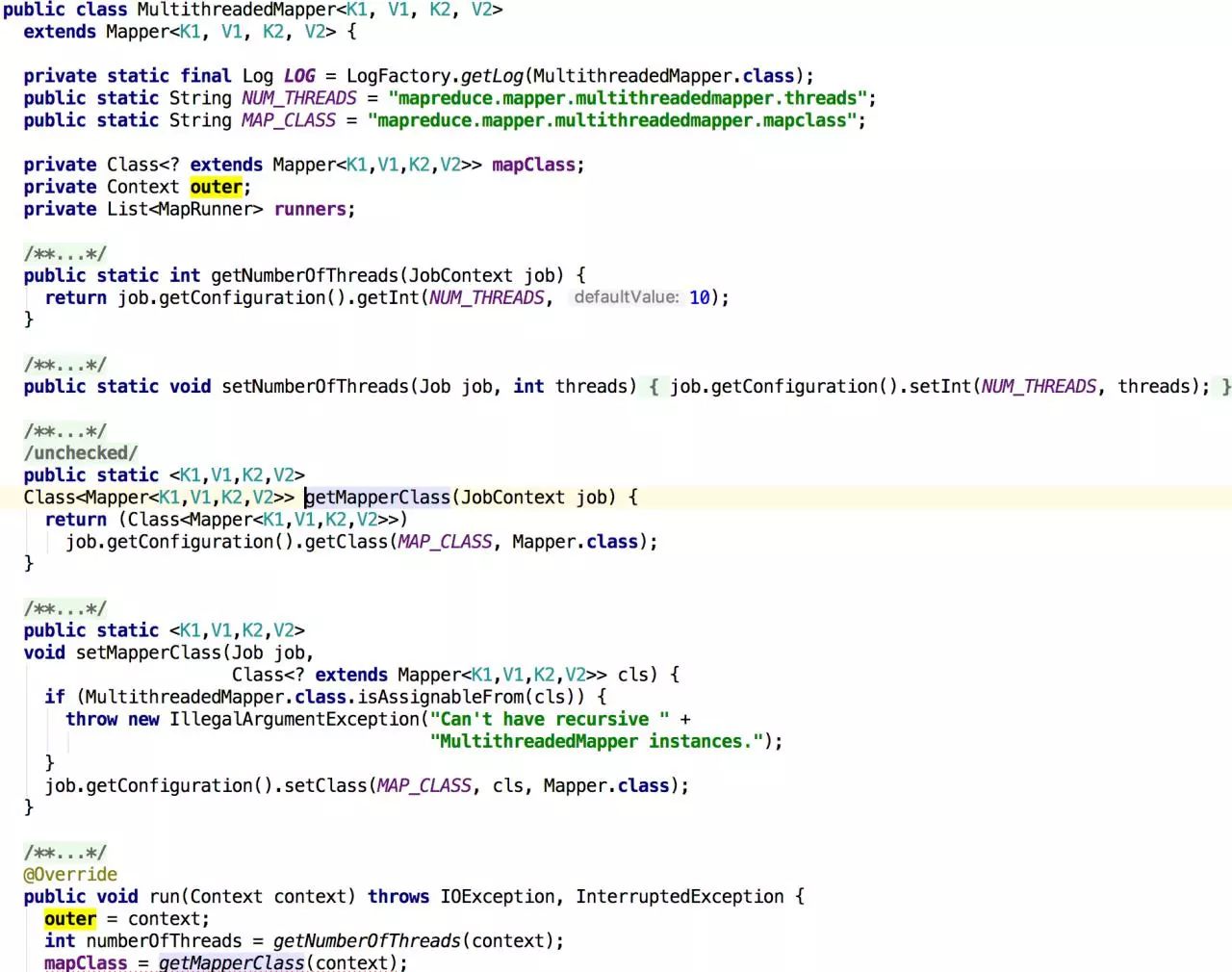
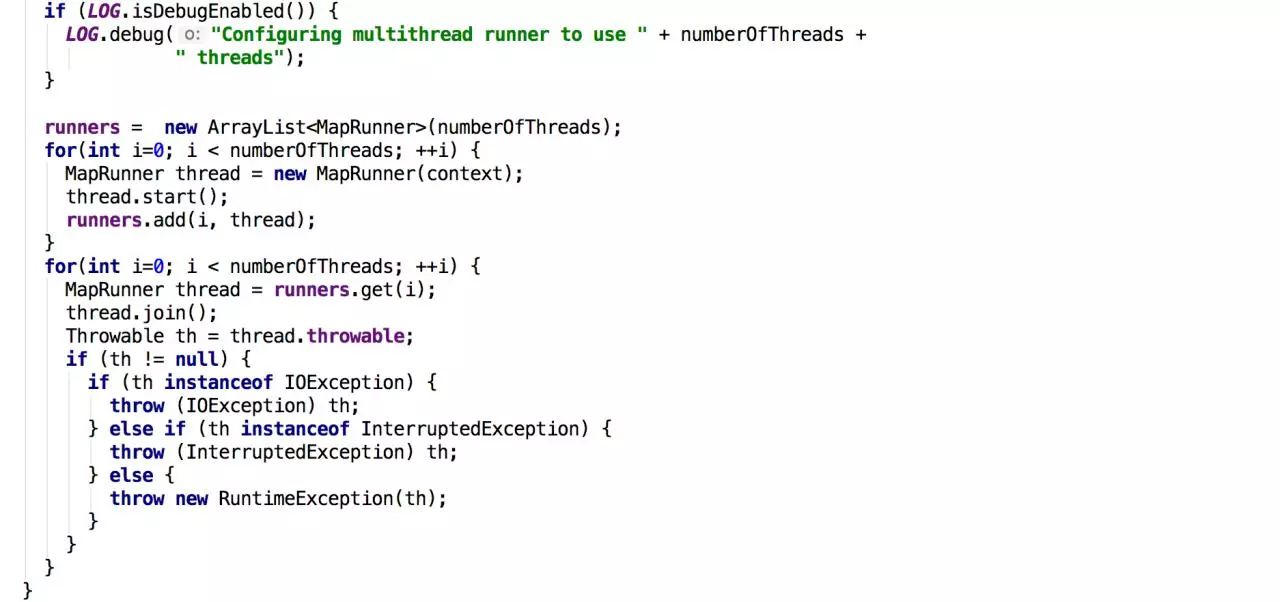
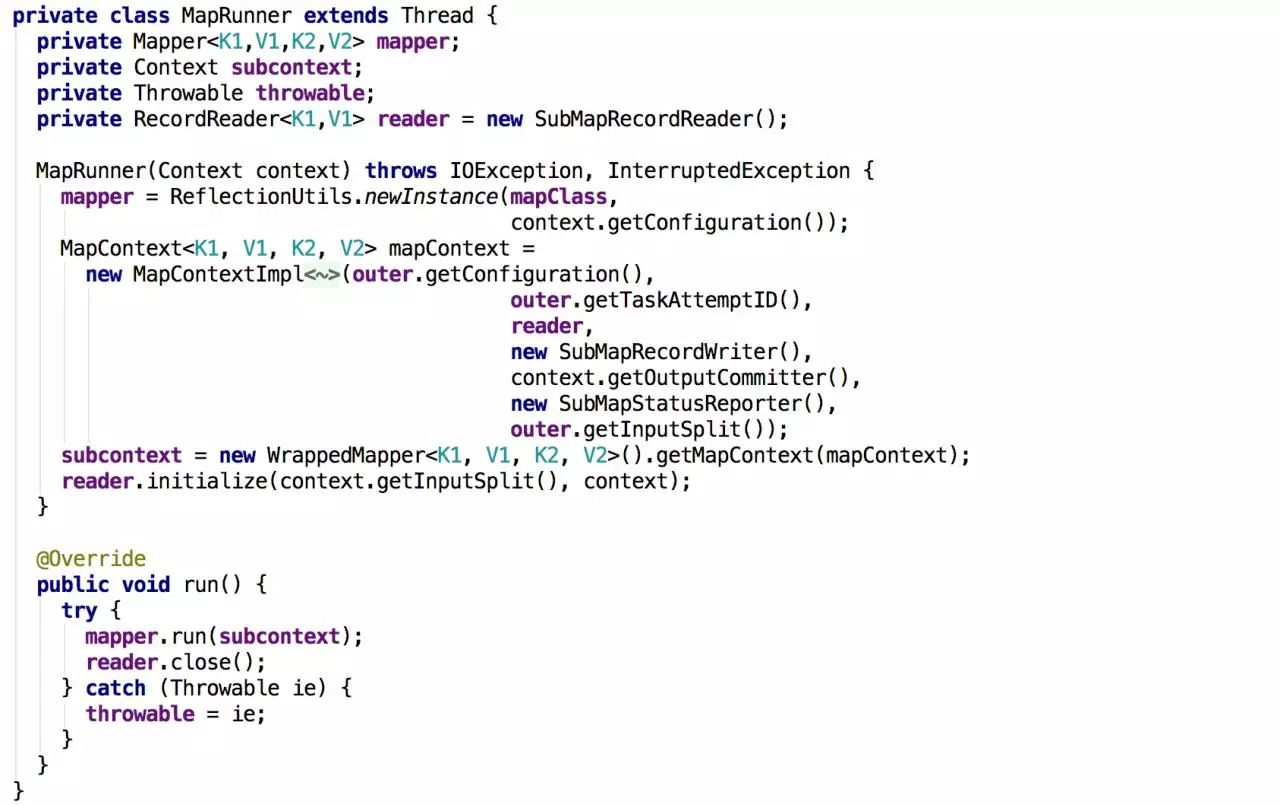
这个类使用多线程来执行Mapper(它由mapreduce.mapper.multithreadedmapper.mapclass设置)。该类重写了run()方法,首先设置运行上下文context和workMapper,然后启动多个MapRunner(内部类)子线程(由mapred.map.multithreadedrunner.threads 设置 ),最后使用join()等待子线程执行完毕。MapRunner(内部类)继承了Thread,拥有独立的Context去执行Mapper,并进行异常处理。从MapRunner的Constructor中我们看见,它使用了独立的SubMapRecordReader、SubMapRecordWriter和SubMapStatusReporter。SubMapRecordReader在读Key-Value和SubMapRecordWriter在写Key-Value的时候都要同步。这是通过互斥访问MultithreadedMapper的上下文outer来实现的。MultithreadedMapper可以充分利用CPU,采用多个线程处理后,一个线程可以同时在另一个线程执行的时候读取数据并执行,这样就使用了更多的CPU周期来执行任务,从而提高吞吐率(注意读写操作都是线程安全的)。但对于IO密集型的作业,采用MultithreadedMapper会适得其反,因为会有多个线程等待IO,IO便成为限制吞吐率的关键,这时候我们可以通过增多task数量的方法来解决,因为这样在IO上就是并行的。
以上即是对MapReduce中Mapper以及部分子类源码的解析,后续将继续讨论MapReduce中的其他关键类源码。
