


导读
上一篇文章介绍了MapReduce中Map(映射)的实现者Mapper,本章将会介绍MapReduce中的输入文件读取者InputFormat。MapReduce程序获取的数据类型多种多样,当程序把数据输入给Mapper时,需要格式化读取,例如读取普通文本文件需要设置job.setInputFormatClass(TextInputFormat.class)。所有的输入格式类都继承于InputFormat,它的主要作用是将输入数据切分成分片(比如多少行为一个分片),以及如何读取分片中的数据(比如按行读取)。前者由getSplits()完成,后者由RecordReader完成。下面我就详细介绍一下InputFormat和它的一些相关类是如何实现数据的输入和读取的。
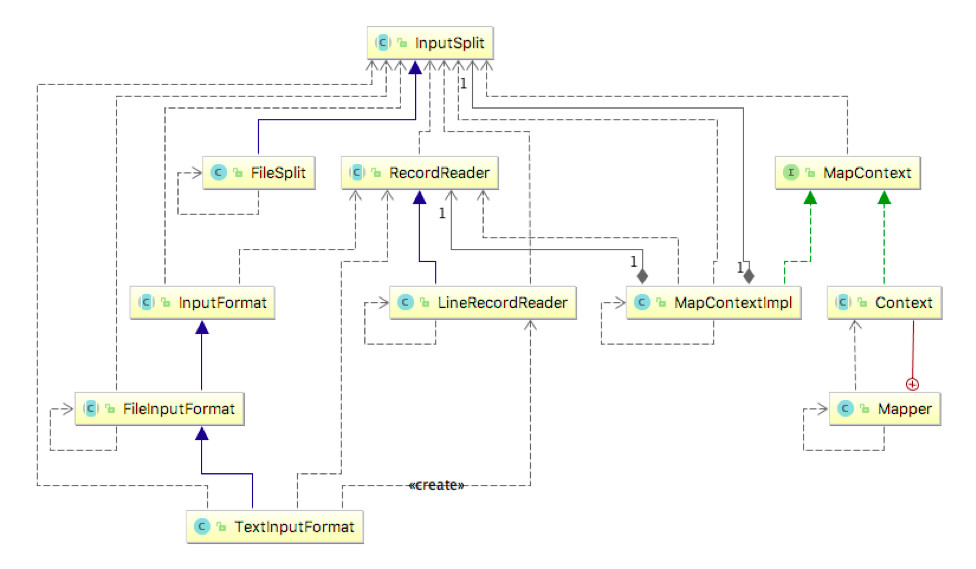
类图
InputFormat源码
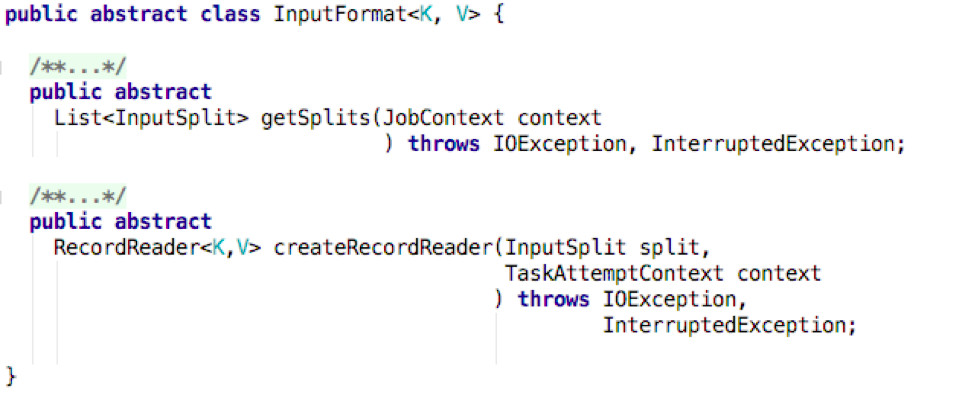
InputFormat是一个抽象类,有两个抽象方法:
1. getSplits() 负责将文件切分成多个分片(InputSplit),但并没有实际切分文件,而只是说明了如何切分数据,InputSplit只是逻辑上的切分。例如,可以拆分为<input-file-path,start,offset>元组。
2. createRecordReader() 则创建了RecordReader,用来从InputSplit读取记录。例如,LineRecordReader以偏移值为Key,一行的数据为Value,它将以K-V对从InputSplit中正确读出来。
InputSplit源码
InputSplit也是一个抽象类,InputFormat通过getSplits()切分成的分片就存储在这个类中,它在逻辑上包含了提供给处理这个InputSplit的Mapper的所有K-V对。
1.getLength() 用来获取InputSplit的大小,以便对InputSplit进行排序。
2.getLocations() 则用来获取存储分片的位置列表,这些位置是本地的,不需要序列化。
3.getLocationInfo() 获取有关输入拆分存储在哪些节点,以及如何在每个位置存储信息。
RecordReader源码
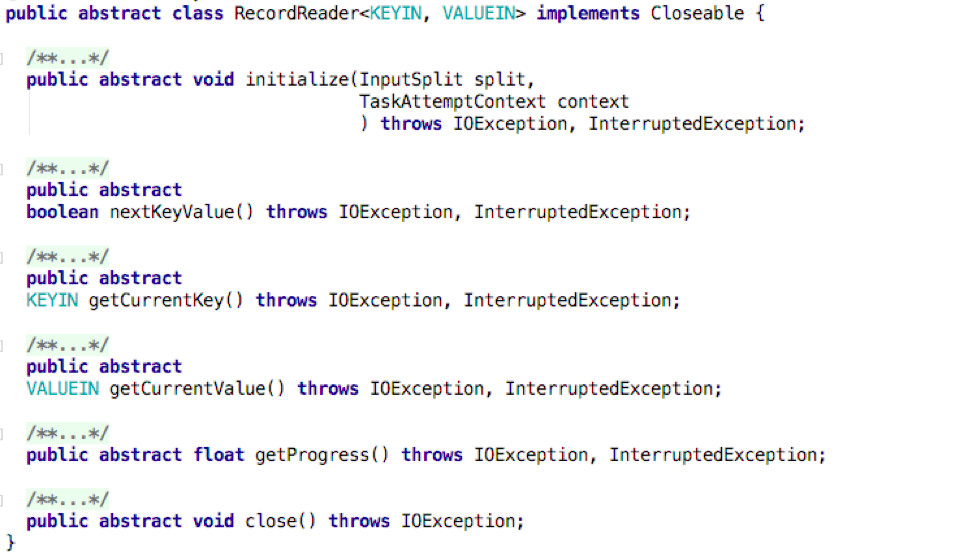
RecordReader是用来从一个输入分片中读取一个一个的K-V对的抽象类,我们可以将其看作是InputSplit上的迭代器。
initialize() 初始化RecordReader。
1. nextKeyValue() RecordReader中最主要的方法,由它获取分片上的下一个K-V对。
2. getCurrentKey() 获取当前的Key。
3.getCurrentValue() 获取当前的Value。
4.getProgress() 记录RecordReader当前通过其数据的进展。
5.close() 关闭RecordReader。
具体实现 (按行读取数据)
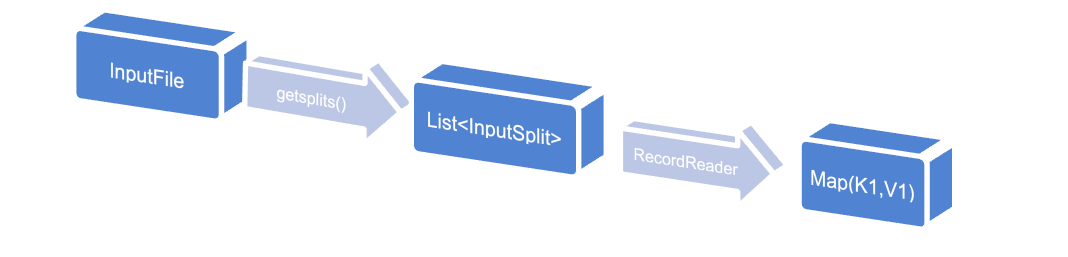
Sept1:通过getSplits()获取文件切分
FileInputFormat(InputFormat的子类)中的getSplits()

主要功能:
1.获取InputSplit的SplitSize。可以通过设置mapred.min.split.size和mapred.max.split.size来设置,默认情况下min为1,max为block的大小。
2.判断文件是否可以切分。比如,密码文件、压缩文件只能按照一个分片进行处理。
3.通过computeSplitSize计算出splitSize。计算方法是:Math.max(minSize, Math.min(maxSize, blockSize))。也就是保证在minSize和maxSize之间,且如果minSize<=blockSize<=maxSize,则设为blockSize。
4.通过add()将分片加入列表,该方法中通过makeSplit()实现逻辑块的切分。
5.分析文件长度不为0程序如何执行。
样例:
文件大小300,length=300,bytesRemaining=300
执行第一次makeSplit(0,128) 按splitSize=128切分
bytesRemaining=300-128=172
执行第二次makeSplit(300-172=128,128)
bytesRemaining=172-128=44
执行第三次makeSplit(300-44=256,128)
Sept2:通过createRecordReader()处理Map任务
TextInputFormat(FileInputFormat的子类)中的createRecordReader()
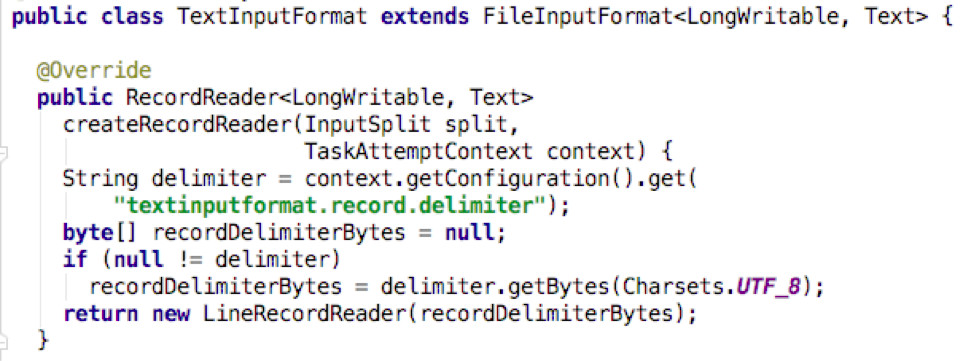
主要功能:
1.设置终止符。textinputformat.record.delimiter 指的是读取一行的数据的终止符,即遇到终止符时,这一行的读取结束。可以通过Configuration的set()方法来设置自定义的终止符,如果没有设置,那么Hadoop就采用以CR,LF或者CRLF作为终止符。
2.获取一个LineRecordReader对象,读取InputSplit。
LineRecordReader(RecordReader的子类)nextKeyValue()
主要功能是通过nextKeyValue()方法给Key和Value赋值。由readLine()方法从输入流中读取给定文本,返回值为被读取字节的数量 newSize = in.readLine(value, maxLineLength, maxBytesToConsume(pos))。读取一行数据,将数据放入value中,返回值为被读取字节的长度,还包括新行(换行)。
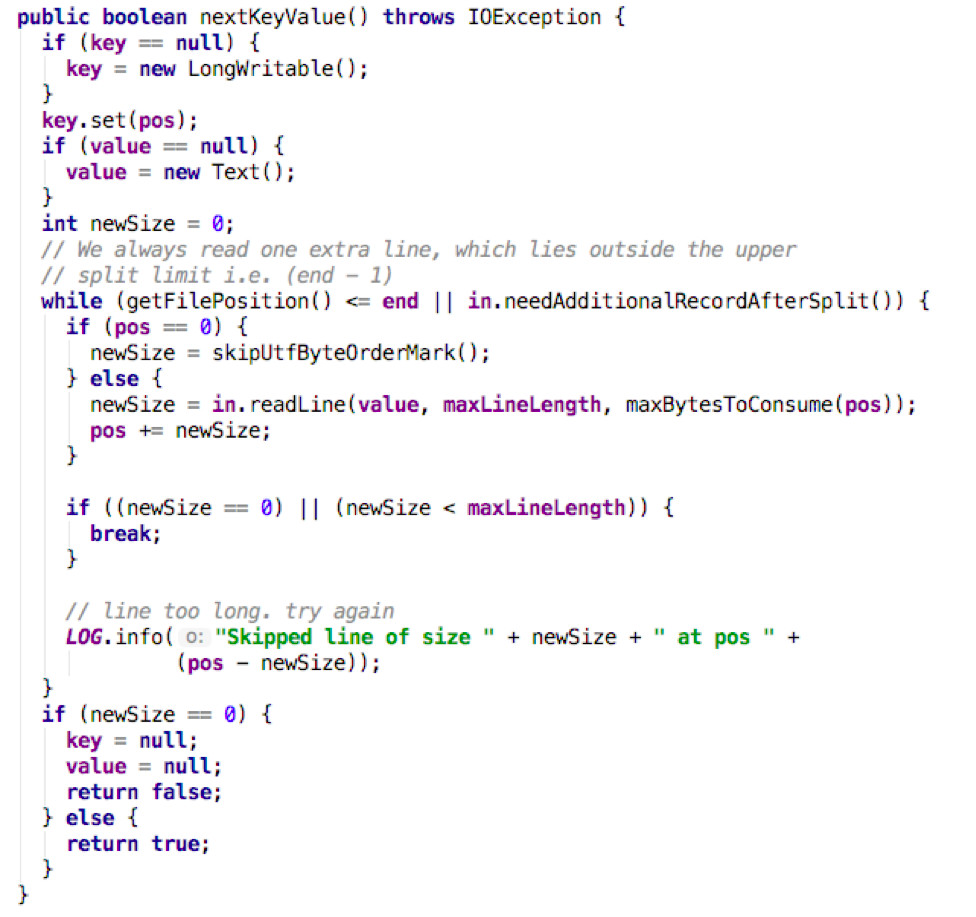
样例:
hello analysys
hello me
上述文件会被切分成一个Split
第一次调用nextKeyValue()的时候start=0,value=hello analysys,end=24, pos=0,key=0,newsize=15
第二次调用nextKeyValue()的时候key=15,value=hello me,newsize=10
Sept3:通过run()调用nextKeyValue()
Mapper中的run()
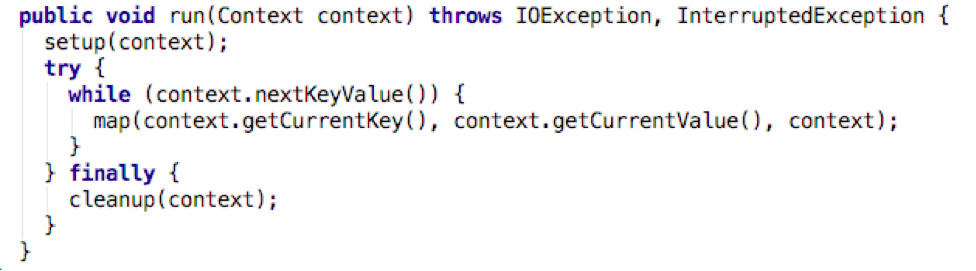
主要功能是通过Context中nextKeyValue()读取RecordReader中的<Key,Value>数据。
MapContextImp(MapContext的子类,MapContext在Context中构造)中的run()
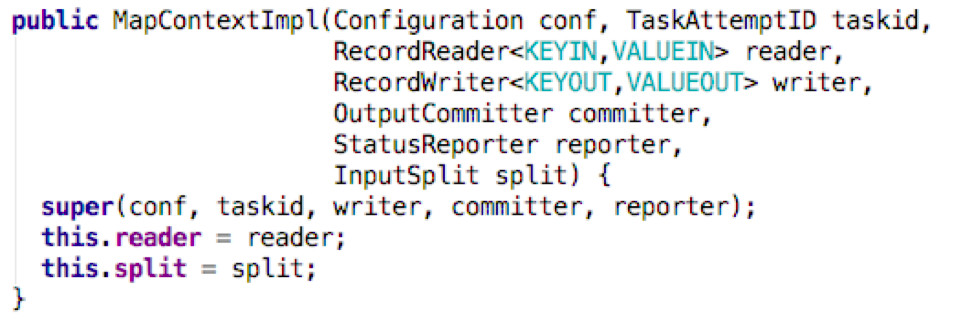
主要功能是使用了一个RecordReader进行构造。
以上就是MapReduce中InputFormat以及相关类源码的解析,后续将继续讨论MapReduce中的其他关键类源码。
