


导读:基于数据驱动的运营已经成为众多行业的核心竞争力,但是对于很多中小型企业或团队面临很多现实的问题,大数据技术人员配备不足,硬件资源预算有限,尤其对于产品处于投放初期,仅靠负责业务线开发的技术人员支撑数据分析需求,就会出现响应不及时、覆盖需求面过于单一等问题。
过去传统的中心化、非实时化数据处理的思路显然已经不符合企业发展的需要。
易观方舟Argo核心是IOTA架构,IOTA是易观经过多年技术实践沉淀下来的大数据实时分析技术架构。易观方舟Argo的设计初衷就是让技术人员单机玩转百亿大数据,我们特别邀请易观相关技术人员,解析易观方舟Argo如何做到让用户低成本、本地化处理大数据、进行大数据分析。
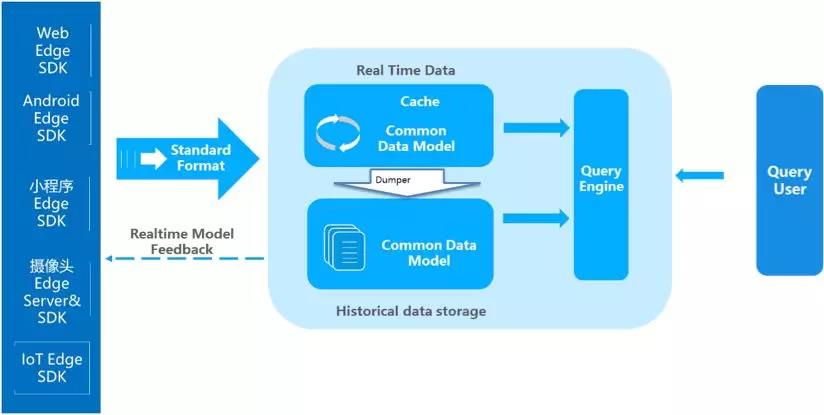
整体技术结构分为几部分:
Common Data Model:贯穿整体业务始终的数据模型,这个模型是整个业务的核心,要保持SDK、cache、历史数据、查询引擎保持一致。对于用户数据分析来讲可以定义为“主-谓-宾”或者“对象-事件”这样的抽象模型来满足各种各样的查询。以大家熟悉的App用户模型为例,用“主-谓-宾”模型描述就是“X用户 – 事件1 – A页面(2018/4/11 20:00) ”。当然,根据业务需求的不同,也可以使用“产品-事件”、“地点-时间”模型等等。模型本身也可以根据协议(例如 protobuf)来实现SDK端定义,中央存储的方式。此处核心是,从SDK到存储到处理是统一的一个Common Data Model。
Edge SDKs & Edge Servers:这是数据的采集端,不仅仅是过去的简单的SDK,在复杂的计算情况下,会赋予SDK更复杂的计算,在设备端就转化为形成统一的数据模型来进行传送。例如对于智能Wi-Fi采集的数据,从AC端就变为“X用户的MAC 地址-出现- A楼层(2018/4/11 18:00)”这种主-谓-宾结构,对于摄像头会通过Edge AI Server,转化成为“X的Face特征- 进入- A火车站(2018/4/11 20:00)”。也可以是上面提到的简单的APP或者页面级别的“X用户 – 事件1 – A页面(2018/4/11 20:00) ”,对于APP和H5页面来讲,没有计算工作量,只要求埋点格式即可。
Real Time Data:实时数据缓存区,这部分是为了达到实时计算的目的,海量数据接收不可能海量实时入历史数据库,那样会出现建立索引延迟、历史数据碎片文件等问题。因此,有一个实时数据缓存区来存储最近几分钟或者几秒钟的数据。这块可以使用Kudu或者Hbase等组件来实现。这部分数据会通过Dumper来合并到历史数据当中。此处的数据模型和SDK端数据模型是保持一致的,都是Common Data Model,例如“主-谓-宾”模型。
Historical Data:历史数据沉浸区,这部分是保存了大量的历史数据,为了实现Ad-hoc查询,将自动建立相关索引提高整体历史数据查询效率,从而实现秒级复杂查询百亿条数据的反馈。例如可以使用HDFS存储历史数据,此处的数据模型依然SDK端数据模型是保持一致的Common Data Model。
Dumper:Dumper的主要工作就是把最近几秒或者几分钟的实时数据,根据汇聚规则、建立索引,存储到历史存储结构当中,可以使用map reduce、C、Scala来撰写,把相关的数据从Realtime Data区写入Historical Data区。
Query Engine:查询引擎,提供统一的对外查询接口和协议(例如SQL JDBC),把Realtime Data和Historical Data合并到一起查询,从而实现对于数据实时的Ad-hoc查询。例如常见的计算引擎可以使用presto、impala、clickhouse等。
Realtime model feedback:通过Edge computing技术,在边缘端有更多的交互可以做,可以通过在Realtime Data去设定规则来对Edge SDK端进行控制,例如,数据上传的频次降低、语音控制的迅速反馈,某些条件和规则的触发等等。简单的事件处理,将通过本地的IOT端完成,例如,嫌疑犯的识别现在已经有很多摄像头本身带有此功能。
IOTA大数据架构主要有如下几个特点:
去ETL化:ETL和相关开发一直是大数据处理的痛点,IOTA架构通过Common Data Model的设计,专注在某一个具体领域的数据计算,从而可以从SDK端开始计算,中央端只做采集、建立索引和查询,提高整体数据分析的效率。
Ad-hoc即时查询:鉴于整体的计算流程机制,在手机端、智能IOT事件发生之时,就可以直接传送到云端进入real time data区,可以被前端的Query Engine来查询。此时用户可以使用各种各样的查询,直接查到前几秒发生的事件,而不用在等待ETL或者Streaming的数据研发和处理。
边缘计算(Edge-Computing):将过去统一到中央进行整体计算,分散到数据产生、存储和查询端,数据产生既符合Common Data Model。同时,也给与Realtime model feedback,让客户端传送数据的同时马上进行反馈,而不需要所有事件都要到中央端处理之后再进行下发。
IOTA是易观方舟Argo的核心架构,作为一个轻量级的大数据处理工具,易观方舟Argo“麻雀虽小五脏俱全”,易观方舟Argo架构分为5层,分别是:采集层、接收层、数据层、服务层、应用层及贯穿平台始终的数据治理服务。其中:
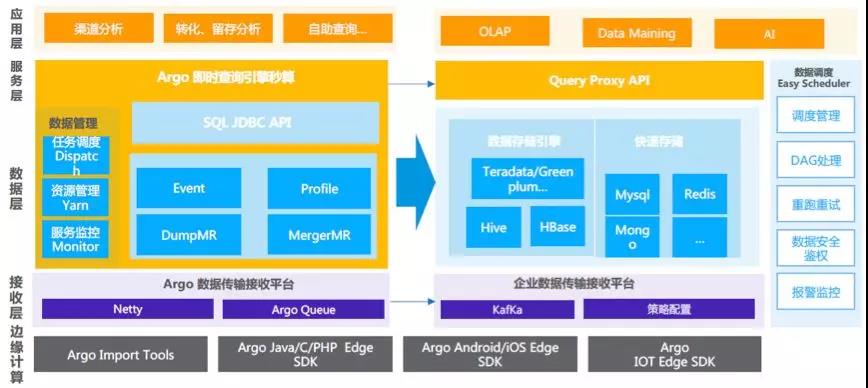
1、采集层
数据采集层分客户端采集和服务段采集,客户端采集sdk包括android sdk、ios sdk、小程序sdk、JS SDK、IOT设备sdk,服务端采集sdk包括java、C、C#、python、ruby等多种语言sdk包。另外方舟还提供数据导入工具,支持导入历史数据以及其他业务系统数据。
2、接收层
接收层负责收集移动端App、网页端以及服务器端等大量的日志数据、对数据进行过滤和处理,并返回数据处理结果以及上报策略给sdk,便于sdk及时调整上报策略。
3、数据层
数据层采用大数据IOTA架构,整体思路是设定标准数据模型,通过边缘计算技术把所有的计算过程分散在数据产生、计算和查询过程当中,以统一的数据模型贯穿始终,从而提高整体的运算效率,同时满足实时计算的需要,可以使用各种Ad-hoc Query来查询底层数据。
4、服务层
服务层即data-api层,通过Argo即席查询秒算引擎为应用层标准Restful查询接口。
5、应用层
应用层就是在服务层上建立的各种系统的应用
基于SpringBoot的微服务架构:
微服务平台按功能服务模块化拆分, 主要分为:公共组件模块(登录、注册、短信、推送等)、数据分析模块(运营分析、用户画像、用户触达)
基于ambari二次开发的统一监控平台(hadoop&spark大数据生态及微服务整体)
基于springboot的后台管理系统(维护系统的元数据、权限及配置信息等)
后续文章将陆续介绍数据采集SDK、秒算引擎等易观方舟Argo核心模块的技术原理,敬请关注。

